Abridged Version: Complete Notes Available Here.
Total Score = ([Attendance]*0.1+[Quizzes and Assignments]*0.25+[Midterm Score]*0.25+[Final Exam Score]*0.4)+[Extra Credit]
Quizzes and Assignmentgs = ([Enrolling]*0.5+[Quiz One: Microcase Intro]+[Quiz Two: Percents and Expected Frequencies]+[Percent Recalculation]*0.5+[Quiz Three: Wbk 2a + Ch 1 & 6]+[Quiz Four: Workbook 2b ]+[Quiz Five: Measurement and Sampling]*1.5+[Conceptualization]*0.5+[Quiz Six: Causal Analysis]+[Quiz Seven: The Crime Drop]+[Excel Regression]*1.5+[Multivariate CrossTabs]*2+[Human Subjects]*2+[Quiz 8: Workbook Chapter 8]+[Quiz Nine: Field Research and Content Analysis]+[PosterSession]+[Library Alt to Poster]+[Quiz 10: Multiple Choice Review for Final]+[Quiz Eleven: Statistics Review for Final])/19.5
- Note: you could have a score for either Poster Session or Library Alternative to Poster Session, but not both -
April 25 Review for the final:
The Textbook is well designed for reviewing, especially the "review glossaries" at the end of each chapter. There are also chapter summaries at the beginning of each chapter of the Workbook.
There are also two Review Quizzes that will open from April 27 to May 2. These are required and may be taken as many times as you like until May 2. The answers will be released on May 3. The exam is on May 4 at 2 p.m.
Here are some points covered with multiple choice questions:
- The differences between survey research, field research,
experimental research, focus groups and content analysis. See
- Lineup
Experiment - as an example of experimental research
- The field research, content analysis and other studies covered in the last two weeks of class. If you weren't in class, you can check these out on the notes.
- History effects, maturation effects, testing effects, regression to the mean and subject mortality in experimental research.
- Ethical issues in research with human subjects: the Belmont
report, definition of "research", behavioral vs. biomedical research
- Criteria for establishing causation. Independent, dependent, antecedent and intervening variables.
- Levels of measurement: dichotomous, nominal, ordinal, interval and ratio. The levels of measurement required to use statistical techniques such as percentages, chi square, correlation, regression, means, standard deviation.
- Interpreting a time series graph, such as those we did with the Historical Trends module of WEBCT. Fitting a linear regression equation to a time series graph.
- Tests of reliability: inter-rater, test-retest, internal consistency.
- Tests of validity: criterion, construct, convergent, face.
- Types of samples: simple random, stratified, quota, systematic, cluster.
- Interpretation of scattergrams, e.g., height and weight.
- Inferential
and descriptive
statistics and their requirements in terms of data measurement
quality. See the Statistics
Overview page.
- Some of these are covered in the Multiple Choice Review for the
Final in WEBCT, but not all. Others are covered in the exams we
have taken earlier in the semester. You can access all your old
exams through WEBCT. It would also be helpful to review the
Midterm exam.
- row, column and total percents when asked for in a sentence
- expected frequencies
- margins of error for percentages and mean scores
- frequency distributions, means and standard deviations - see the Descriptive
Statistics page.
- compute predicted values with regression equations, similar to the exercise done in class on April 18 (the answers are below). These same questions are in the Statistics Review for the Final in WEBCT .
- specify the regression equations needs to get the coefficients
for a path diagram. See the examples on the Path Analysis
Handout. You do not need to include the b coefficients or the
error term e.
- If you can do all the items in the Statistics Review for the
Final in WEBCT, you should be fine. The test will include a copy
of some of the necessary Formulas.
-
Content Analysis - "unobtrusive data" Data created by a bureaucratic system, e. g. police records, or often by the media. Television or Newspapers either because that is our interest, the media, or as a way of getting information, e.g., on crime reported in the news.
Similar to survey research, except that you do coding instead of interviewing. Coding means that you assign numbers to phenomena that you observe. Counting things. Each of your variables is coded from the published information.
Conceptualization.
Measurement. Reliability and Validity.
Latent Content - things that we infer about the content, e.g., does the writer sound angry? Indignation, sexy?
A Content Analysis Study of Editorial Cartoons.
A Content Analysis of Internet-Accessible Written Pornographic Depications.
We can use the content analysis study as an illustration of many of the basic concepts from the first part of the semester that will be on the second midterm and again on the final. We can use the definitions in the Review Glossaries in the textbook. I am not going to repeat these definitions in the notes.
April 11 - Some examples of field resarch:
Margaret Mead, the only anthropologist (or
 sociologist)
to get her own postage stamp, won fame through field work, primarily
her
book Coming
of Age in Samoa. Later, this book was denounced by
anthropologist
Derek Freeman in his book Margaret
Mead and the Heretic : The Making and Unmaking of an Anthropological
Myth.Anthropologists
have come to Mead's defense, and
have restudied the case, but I would have to agree with your text
that
"had Mead come back from Samoa with an accurate ethnographic report, it
would not have made her famous."
sociologist)
to get her own postage stamp, won fame through field work, primarily
her
book Coming
of Age in Samoa. Later, this book was denounced by
anthropologist
Derek Freeman in his book Margaret
Mead and the Heretic : The Making and Unmaking of an Anthropological
Myth.Anthropologists
have come to Mead's defense, and
have restudied the case, but I would have to agree with your text
that
"had Mead come back from Samoa with an accurate ethnographic report, it
would not have made her famous." More recently, there has been a raging controversy about the book Darkness in El Dorado about research on the Yanomamo in Venezuela is the latest ethical controversy, which also raises important methodological questions. Many of the book's allegations, however, have been contested by the National Academy of Sciences.
The combining of fiction with factual research is increasingly common both in anthropology and in biographies. Sometimes this is
 openly
done as a literary form, in other cases such as that of Rigoberta
Menchu,
it is only admitted when
critics discover it.
The
Rigoberta Menchu Controversy by Arturo Arias.
openly
done as a literary form, in other cases such as that of Rigoberta
Menchu,
it is only admitted when
critics discover it.
The
Rigoberta Menchu Controversy by Arturo Arias. There are many problems with field research: ethical issues, problems of reliability and validity when data are gathered by only one researcher, etc. A controversial book is Laud Humphrey's Tea Room Trade, which raises ethical issues. He studied gay sex in a men's room in a park in St. Louis, without informing the participants what he was doing.
Field researchers sometimes seem to find examples that fit their preconceptions, and their work is often ignored by those who do not like the results, e.g., Leon Dash's book When Children Want Children and Rosa Lee which are just ignored by welfare advocates who prefer more sympathetic treatments. One of the best field studies is Kathryn Edin's book Making Ends Meet. which is highly sympathetic to the mothers. However, Edin collected statistical data as well her illustrative observations. The statistics showed that almost none of the mothers actually lived off their grants alone. Eli Anderson's book Streetwise on men in a Philadelphia ghetto has been well received, in large part because goes beyond one-sided advocacy.
James Flatley, Etienne Jackson and Robert Wood's Video version of Down Germantown Avenue.
A great strength of field work is observing behaviors that the people themselves don't understand or aren't even aware of., or at any event, are unable or unwilling to talk about. Anthropologist Jules Henry spent a week living in each of the homes of several children who had grown up mentally ill,
 trying
to discern patterns in the family interactions that contributed to the
illness. Myra Bluebond-Langner's book The
Private Worlds of Dying Children has been very influential;
she
has just published a sequel called In
the Shadow of Illness : Parents and Siblings of the Chronically Ill
Child
Field reserch offers a richness of description and possibility of new
insights
that is unparalled by any other method. Unless it is supplemented
with other methods, it does not provide statistical data, and it is
hard
to replicate.
trying
to discern patterns in the family interactions that contributed to the
illness. Myra Bluebond-Langner's book The
Private Worlds of Dying Children has been very influential;
she
has just published a sequel called In
the Shadow of Illness : Parents and Siblings of the Chronically Ill
Child
Field reserch offers a richness of description and possibility of new
insights
that is unparalled by any other method. Unless it is supplemented
with other methods, it does not provide statistical data, and it is
hard
to replicate.
Myra Bluebond-Langner of our Anthropology Department wrote a classic, The Private Worlds of Dying Children, and more recently, In The Shadow of Illness.
Coming of Age in New Jersey.
The Corner. Memoirs: Frey dispute with Oprah.
Black American Students in an Affluent Suburb. by John Ogbu.
Commentary on Ogbu's research.
Many scholars who have disputed those findings rely on a continuing survey of about 17,000 nationally representative students, which is conducted by the National Center for Education Statistics, an arm of the federal government. This self-reported survey shows that black students actually have more favorable attitudes than whites toward education, hard work and effort.
But that has by no means settled the debate. In the February issue of the American Sociological Review, for example, scholars who tackled the subject came to opposite conclusions. One article (by three scholars) said that the government data were not reliable because there was often a gap between what students say and what they do; another article by two others said they found that high-achieving black students were especially popular among their peers.
"It's difficult to determine what's going on," said Vincent J. Roscigno, a professor of sociology at Ohio State University who has studied racial differences in achievement. "'I'm sort of split on Ogbu. It's hard to compare a case analysis to a nationally representative statistical analysis. I do have a hunch that rural white poor kids are doing the same thing as poor black kids. I'm tentative about saying it's race-based."
Indeed, Professor Mickelson of the University of North Carolina found that working class whites as well as middle-class blacks were more apt to believe that doing well in school compromised their identity.
All these years later, Professor Fordham said, she fears that the acting-white idea has been distorted into blaming the victim. She said she wanted to advance the debate by looking at how race itself was a social fiction, rooted not just in skin color but also in behaviors and social status.
"Black kids don't get validation and are seen as trespassing
when they exceed academic expectations," Professor Fordham said,
echoing her initial research. "The kids turn on it, they sacrifice
their spots in gifted and talented classes to belong to a group where
they feel good."
April 6
What is a rate? Take a number and divide it by a base. Usually the base is the population, or some group within the population. If we look at the birth rate, want to control for the size of the state. Or you may to control for the number of women or childbearing age. In terms of voting, the base is often the number of eligible voters, or of people of voting age.
Aggregate data gives you overall patterns, they may apply to individuals. A case-oriented approach vs. variable-oriented.
The base of a percent often makes a big difference.
Exceptional cases may distort a "variable-oriented" analysis, e.g., including Washington DC in an analysis distorted the correlation between percent black and percent with graduate degrees.
Doing the multivariate cross-tabulation table.
You start with your dependent variable which you put in the row. You put your independent variable in the column. For the total sample table, you just cross-tabulate these two variables. Then you introduce the control variable. This will give you "partial" tables, tables for only part of the data set. In the case of "Drinking by Education by Age, the partial tables are for age groups: under 30, 30 to 49, 50+
Another example. Use the Student data set and software, with the 1998 GSS data Set. We will not have so many cases. We will do
Respondent's Income by Education by Age
Respondent's income is the row variable because it is dependent. Education is the Column Variable, Age is the Control Variable
Not HS HS College Not HS HS College Not HS HS College
Under $17,000 67% 41% 20% 44% 36% 13% 60% 40% 18%
$17,000 to $34,000 22% 40% 37% 39% 36% 26% 27% 39% 35%
$35,000 plus 10% 19% 43% 17% 28% 61% 13% 21% 47%
N = 106 786 528 52 213 157 158 1001 685
p = .000 p = .000 p = .000
Respondents with a college education are more likely to have a high income. 47% of the respondents with a college education were in the highest income category, as comapred to only 13% of those who did not graduate high school. This was true both for the respondents who were under 50 years of age and for those who were 50 or older. The difference was larger for the older respondents. Among the respondents who were over 50, 61% were in the highest income category, as compared to 17% of those without a high school degree. For the respondents under 50 years of age, 43% of those with college degrees were in the highest income category, as compared to only 10% of those without a high school degree.
March 31: Uses of the Linear Equation:
Causal questions:: Do storks bring b abies? What is our IV? What is our DV? What test variable would we introduce?
Does attending an Ivy League College Bring Success in Later Life? What test variables?
One way to think of causal relationships is with The Elaboration Paradigm:
Elaboration Paradigm compares bivariate to multvariate
relationships.
In a Bivariate Relationship you have an IV and DV. A cause and
an Effect.
We introduce a TEST VARIABLE to see whether the relationship is causal.
Test Variable
Partial relationship
compared with Original
Antecedent Intervening
Same relationship Replication Replication
Less or none Explanation Interpretation (explanation is a synonym for "spurious")
Split
Specification Specification
(Split means that one partial is the same or greater, while the other
is less or none).
One method of testing this is to use multivariate
cross-tabulation. See the example on marital status and frequency
of sex we did on March 21. This
means we introduce a third Test or Control variable and examine
the relationship between the IV and the DV for each of the values
of the Test Variable. We compare this to the relatinship for the
Total Sample. This method works with variables that have only a
few values - two or three are best. If we have continuous
variables, we can either recode them into categories, or use multiple
regression and path analysis instead.
Another
example is
Newspaper Reading by Income by Age Groups (a Word file).
Essential characteristics:
- Two or more groups are matched, usually by random assignment, sometimes by a kind of stratified random selection, e.g., an equal number of men and women or black sand whites in each group. But the key is random assignment so that the groups can be assumed to be the same on all variables. "Quasi-experiments" are when we use groups that are pretty much the same but we didn't assign people at random
- The Independent Variable is "manipulated," i.e., it is applied to one group and not to the other
- Change in the Dependent Variable is measured
- In laboratory settings with volunteers, e.g., student volunteers
- In institutional settings such as prisons, hospitals, rehabilitation centers, etc., where people are assigned to treatment groups
- New drugs and medical treatments generally must
be shown
to work in experiments before they are approved for use. Often,
 treatment
is compared to a placebo. These experiments are usually
"double-blind,"
to control for the psychological effects of knowing one is getting
treatment.
This is a way of controlling subject bias and experimenter bias/
treatment
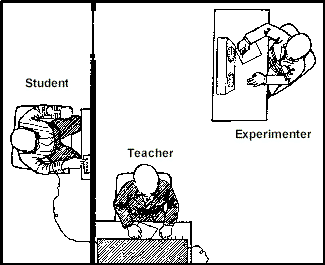
is compared to a placebo. These experiments are usually
"double-blind,"
to control for the psychological effects of knowing one is getting
treatment.
This is a way of controlling subject bias and experimenter bias/ - In criminal justice, one might do an experiment comparing a "half way house" to drug treatment program to a prison term for offenders. To do this, you would have to get the judge to assign offenders to different programs at random. Ethical issues are raised here and there are likely to be objections
- Occasionally in natural settings, for example
- welfare reform
experiment, assign some recipients to the
old program, some to
 the
new. This didn't work very well, there
were
errors in the group assignments and the women often forgot which group
they were in anyway
the
new. This didn't work very well, there
were
errors in the group assignments and the women often forgot which group
they were in anyway - vaccination experiments
- guaranteed annual income experiments
- It may be hard to manipulate the independent variable effectively, it may not have enough importance to people that they notice it
- Experimental conditions may not be realistic enough, e.g., the Milgram experiments having people apply electric shock to people, experiments that simulate being in prison. An experiment is not the real world and people know it. This is called external validity, does the experiment match real world conditions
- There may be problems of internal validity, difficulties in carrying out the experiment:
- "History" effects - the world changes during the experiment, people get older, more mature, they are effected by things in the real world
- Maturation, people get older, learn more
- Testing effects, taking the pretest measure effects people, causes them to change. Sometimes we have a matched but untested control group that is measured only after the experiment.
- Instrument effects, the testing instrument may change. You can't use the same exact test sometimes because people will remember it, so items change
- Regression to the mean, just by chance the people who got extremely high or low scores on a pretest are likely to get more average scores on the second test.
- Subject "mortality" - we may lose people. This is especially a problem in testing things like drug rehabilitation, it works for the people who stick with it, the failures drop out
- Ethical concerns: people may not be willing to be experimented on, or it may be harmful to subject them to experimental conditions, e.g.,
- Tuskeegee syphillis experiment denied some men penicillin. You can only deny an experimental drug if you are not "certain" that it works or if the condition is not serious, e.g., common cold research
- A big strength of experiments is resolving questions that involve different recollections of events, e.g., children's reports of abuse. You don't know what "really" happened and people disagree on how well they accept the recollections of different people. In an experiment, you know what really happened, so you can check the accuracy of perception. We find that children often remember things that didn't really happen. "20/20 report on Child Abuse experiments (VIDEO shown in class from an ABC News 20/20 show aired October 22, 1993, hosted by Hugh Downs. Transcript available at www.transcriptstv.com) demonstrates false memory because we know what really happened since it happened in a controlled experimental setting. This is much more difficult to establish in real life case histories: Loftus: Who Abused Jane Doe? There is other information online on the Kelly Michaels case and other cases.
March 23 - Today we will work with a tool called the Regression Equation. We have already seen this in Microcase when we use the scatterplot program. It illustrates fitting a regression line to data. We are going to learn to do this in Excel with our own data, typed in from any source. Many data sources are available for those doing extra-credit projects.
To understand what this means, we first need to understand what it means to plot an equation on a graph. If we draw two coordinates on a piece of paper or on the whiteboard, we can draw a Cartesian coordinate plane with an x-axis (for our independent variable) and a y-axis (for our dependent variable). Each point on this plane has a numerical address. We can then plot lines on this graph by using a regression equation:
Y = a + b X. where X and Y are our variables, and a and b are parameters or fixed numbers given to us by the computer software.
For example, plot the following lines:
If a is zero and b is one, then Y = X. We can say: if X is 0, Y is 0. If X is 2, Y is 2, etc. If we plot these points on the graph we get a straight diagonal line going from the lower left to the upper right (to be demonstrated in class):
If a is one and b is one, we get a line parallel to the first, but one notch up.
If a is 0 and b is minut one, the line will go down... etc.
is a method that computes equations like this to fit straight lines to bivariate relationships between continuous or linear variables. It works best when the variables are "normally distributed," i.e. when they fit a bell-shaped normal curve with most of the cases near the mean and few extremes. We can see how regression works best by using the scatterplot program in Microcase and the USA data set which has many continuous variables using the US States as the unit of measurement. and clicking on "reg line". For example, the graph of % college and Median family income (open Microcase to see this).
At the bottom it says "Line Equation Y = 2.175 + .001 X. This is the equation straight line that appears on the graph.
What does it mean to say that it is the equation for a line? It means that if you use the equation to plot points on a graph they will look like that line. The more general form of this equation is Y = a + b X where:
X is the independent variable (in this case % college)
Y is the dependent variable (in this case Med Fam $)
a is the "intercept" - this is a "parameter" of the equation which means it stays fixed while the variables vary
b is the "unstandardized regression coefficient" - it is also a paramater.
The software computes the equation for us, which is called "fitting a regression equation to the data".

The graph at the right shows "Anscombe's Quartet" a set of scattergrams designed to make a point - it makes no sense to use a regression line unless your data actually tend to fall along a straight line. In box I, the straight line is a reasonable fit. In the others it is not. Yet each of these data sets is fitted by the same regression line.
I
March 21 - we did Descriptive Statistics for Continuous Variables. The required reading and in-class assignment are linked from the course home page.
March 7
Marital Status and Frequency of Sex by Age
Under 50 50 and Older Total
Divorced Never Divorced Never Divorced Never
Widowed Married Widowed Married widowed Married
Less than Monthly 29.7% 30.8% 77.9% 70.2% 54.7% 34.0%
Monthly or More 70.3% 69.2% 22.1% 29.8% 45.3% 66.0%
TOTAL 100% 100% 100% 100% 100% 100%
p=.75 p=.24 p=.000
There is a statistically significant difference between the divorced or widowed respondents and the never married respondents in their frequency of sex. However, when we control for age, this relationship is no longer significant. Age is an antecedent variable, so the relationship between marital status and frequency of sex is spurious.
Spurious means that it is not causal, the correlation is due to a third variable which is antecedent.
We compare the strength of the correlation in the total sample table with the correlations or percentage differences in the partial sample tables.
If the correlations or percentage differences is jabout the same, we would say that the relationship was confirmed or supported.
If the correlation disappears, we would have to ask whether the control variable was Antecedent or Intervening. If it is antecedent, the relationship is spurious. If it is intervening, we have a causal interpretation.
If it disappears in one case but not in the other, we would say that we have specified the relationship.
March 2:
Probabilistic cause, not an absolute cause, not a
cause
that is sufficient or necessary. "Cigarette smoking causes
cancer." WHat we mean is, smoking cigarettes
increases
the likelihood of getting cancer. How much?
There are multiple causes for everything. What
we
want to find out is how much each thing contributes. There are
also
causal linkages, or indirect causes. A causes B
and then B causes C.
Diagraming causal models. We put the dependent
variable
at the right. We draw arrows going into it for each causal
variable that effects it directly. Then we can
have arrows that go into the arrows, steps into the causal analysis, as
in
this sample file:
http://crab.rutgers.edu/~goertzel/homomale.htm
Criteria of Causation - how do we know that something is a cause of something else.
1. Time Order. The cause comes before
the
effect. Sometimes we sort out the time order theoretically, we
assume
that
education preceeds employment. Or we can use a
research design that involves gathering data at two points in
time.
If
you don't have measurements at two points in time, this
is shaky.
2. Correlation. The two variables vary
together.
When one is high, the other is high OR when one is low the other is
high. This gets at the degree of causation, the
higher the correlation the strong the causal relationship.
3. non-spuriousness, we want to know
that
the correlation is not cause by something else. We can test this
with an
experimental design, if feasible. Or we can use
statistical controls, which are not quite as convincing but its all you
do
in many cases.
We test for non-spuriousness by introducing controls.
Causal Models: representations of the complex
causal
relationships between variables. Variables have different causal
roles, but this is determined by our causal our causal model, it is not
inherent in the variables. One person's cause can be
another's
effect.
Dependent Variable - that is what we want to explain. Often these are opinions or behaviors
Independent Variable - what we use to explain
it.
Often there are traits or physical characteristics, e.g., sex or race,
almost always independent.
If you study the relationship of race on voting, for example, race would be independent and voting dependent.
Antecedent variables, things come before the
independent
variable. This helps us to deal with a causal chain.
Antecedent variable cause IV which causes the DV.
If the antecedent variable "explains" the
relationship,
we have an "explanation", we say it is "spurious".
Intervening Variables, this that are intervening,
e.g.
Race determines ideology which determines the vote.
This is an "interpretation" it tells WHY the causal
relationship exists.
Path
Models: a way of graphically expressing complex causal models.
Size of the sample. How big of a sample do I need? Size of the sample does not depend on the size of the population.
How do we select the sample size? Decide on the margin of error you will tolerate? Margin of error is equal to one divided by the square root of the sample size. Sample of 400, the square root is 20. 1/20 = .05 or 5%. If you interviewed 400, 300 were white, 50 were black and 50 were others. For the blacks, with a sample of 50, we would have a 14% margin of error. For the whites, with a sample of 300, we would have a 5.8% margin or error.
Take 300, the square root of 300 is =
17.32
1 /17.32 = .0577 * 100 = 5.8%
population parameter - what the real figure is
Even if the sampling is done well, the response rate is less than 100%.
Weighting is done to make the sample more like the population.
This formula is for proportions or percents
(if you move the decimal over two)
m = 1/sqrt(n)
Solve for N: m2 =
1/n
n * m2 = 1 n = 1/ m2
If we need a margin of error of 3%, or .03. n = 1/ .032
If you have a sample size and need to know the margin of error, use m = 1/sqrt(n)
If you are given a margin of error and asked how large a sample you need, use n = 1/ m2
In these
formulas
n = the size of the sample (not the population). m =
the margin of error expressed as a proportion, not as a percent.
Thus, if the questions says "we need a margin of error of 5%, then m =
.05.
If our sample is stratified, this means we really have several
sub-samples and we need the same size sample for each of them,
regardless of the size. For example, if we want sample white,
black and Hispanic respondents and make statements about each group, we
need the same size sample of both regardless of their size in the
population. Thus, if we need a margin of error of 5% for each of
the three
groups,
then the answer is 3 * (
n = 1/ m2 ).
If
you need a margin of error for a mean score (an average such as income
in dollars or scores on a test), you need to know the standard
deviation
(sd) and the sample size (N). Ignore any other
information
you are given, including the size of the population.
Use the following
formula:
M
= 2 * sd / SQRT(N)
Suppose
I sample 457 Camden residents and the mean income is $27,541 and
the standard deviation is $3452
M
= (2 * 3452 )/sqrt(457). This result will be in dollars, not
percentages.
M
= 6904
/21.378 =
$322.95.
Confidence
Interval: I am 95% sure that the population figure is
between: $27,218.05 and $27,863.95
Terms:
Margin of Error: How much a sample statistic is likely to vary
from the population parameter. We say that we are 95% sure that
the sample is not off by more than the margin of error. How this
is presented in
NY Times. "19 out of 20" is another way of saying 95%.
Confidence level: we always use a 95% confidence level.
All of this assumes a simple random sample, which means that each person (or other sampling unit) in the population has the same chance of appearing in the sample. In practice, however, we often do not use simple random samples, for several reasons:
- we may not have a list of the population. If we do not, we first divide the sample into sub-groups of some kind (census tracts, blocks, classrooms, organizations, depending on the nature of the study). We then sample the subgroups and list the populations in them . This is called cluster sampling
- We may be interested in differences between sub-groups of the
sample and need to make sure we have enough of them. In this case
we select random samples of each of the relevant sub-groups, and weight
the results appropriately. This is called stratified
sampling.
- Sometimes we just go down a list, which is called systematic sampling. This gives the same results as simple random sampling, unless there is some systematic ordering to the list that causes a distortion
- Sometimes we use non-random or "quota" sampling. This is done for convenience, or because we just want to know what the range of differences is without putting numbers on them.
| Suppose
I did a sample of 400,selected from the 7,357,218 people living in New
Jersey. What is the margin of error? M = 1 /SQRT(N). N is the sample size, not the population size. N = 400. Sqrt of N = 20. 1/20 = .05 or 5%. If I find that 42% agree, that is my population "statistic." The population paramater is the true value, and I would say that I am 95% sure (my confidence level) that the paramater is between 42% - 5% and 42% + 5%. The true value should be between 37% and 47%. Suppose I go to 1000, what is my margin of error? M = 1/SQRT(1000). = 1/ 31.62 = .0316 or 3.2%. The confidence interval is between 38.8% and 45.2%. This applies to statements made about the whole sample. 42% of the respondents said yes, the margin of error is 3.2%. For statements about a subgroup, the N is the number of people in that sub group (genders, races, sports fans). We have a sample of 1200, of whom 800 are white, 300 are black and 100 are Hispanic. 57% of the Hispanics said yes to the item. What is the margin of error for this percent? Since it says "of the Hispanics" our N is the number of Hispanics, or 100. M = 1/SQRT(100) = .10 or 10%. For the black respondents, our margin of error is M=1/SQRT(300). = 1 / 17.32 = .0577 = 5.8% For the white respondents M = 1/SQRT(800) = .03535 or 3.5%. How large a sample do I need to get a 5% margin of error, with a population of 485,321? N = 1/M2 M must be expressed as a proportion, not a percent. M = .05. .05 * .05 = .0025. Sample size = 1/.0025 = 400 Suppose I wish to study the black, white and Hispanic populati0n and I need a margn of error of 5% for each group. How large a sample do I need? The other thing we need to deal with is margins of error for mean scores. Thein a survey of 300 county residents, the mean income is $45,321. We need to have the standard deviation. The Standard Deviation is a measure of variation. The standard deviation is $3521. M = 2 * sd/sqrt(n). N = 300. 2 * 3521/17.31 = $203.29. |
Feb 14 -
Scaling or index construction is when we use a number of items, such as questionnaire items, to measure a more general concept. We can do this by adding them up (in which case your text would call it an "index", although many people still use the term scale) , or they may be ordered from lowest to highest (in which case it is a true scale as the term is used in your book). Your test is an example. I just add up the points, to measure the general variable "knowledge of research methods as covered in the first part of the course." Another approach would be to rank the items from easy to hard and see which you could do. This is tricky, because some people can do the hard ones and not the easy ones. When we make an index or scale, we get measures that can be treated as interval, even if they are not strictly interval. Scaling methods can be more precise, but these are not used as often in sociology or CJ because they are more difficult and the added information is not always needed.
Scaling methods include Thurstone and Guttman Scaling. Likert or summative scaling is actually a method of "index" construction as defined in our book. A powerpoint on Thurstone scaling.
For example, we could scale the seriousness of crimes. There are various methods of measuring this. - paired comparisons means asking a sample of people to rate crimes based on their perceived seriousness.
A very popular test is the Myers-Briggs Type Indicator, based on Jungian personality theory. You can takeseveral free versions of this and related tests online (the Wikipedia article). One of the quickest is a word choice test from similarminds.
Many measurements of crime trends are based on scales that add together a number of crimes, e.g. "violent crime". , 2005. :
U.S. crime rate remains at lowest levels in years
Based on victim surveys, the incidence of violent crime is statistically unchanged from last year.
By Mark Sherman - Philadelphia Inquirer Sept 26, 2005
Quality of Measurement - Reliability and Validity.
Reliability - you get the same thing over and over. Consistency.
inter-rater - two different raters get the same answer.
test-retest, if you take it twice the answers are the same.
internal consistency - are theitems on a test consistent. Chronbach's alpha is a statistic that measure inter-item reliability.
Validity is it "really" measuring what it is supposed to measure.
Face Validity - does it look right?
Predictive or criterion validity - does it predict what we want to predict, some "true" measure. SAT test predicts college or law or medical school grades.
Convergent validity - do several measures give the same result.
Construct validity - does the measure perform as our theory says it should. We use this when we have no criterion. This is the most difficult, it is used when things are inherently difficult to measure.
An example: a study of UFO Abduction Status.
February 7 - Measurement means putting observations into categories. Usually these categories are given numbers, although not always. Sometimes we do this just to keep track of things, e.g., each American has a social security number, we have a library number, a student number, etc.. But often the numbers give us more information than that, e.g., the NJ driver's license gives height in feet and inches. It also gives sex and eye color, which are described in words but could be given arbitrary numbers. But the numbers given for height are not arbitrary. In some sciences, e.g., astronomy, numerical measurement has led to important insights, e.g, to understanding the motion of the planets. This is because our observations can be summarized with mathematical equations that enable us to predict events.When we measure something, we need to be clear exactly what the measure means. Especially when we use a number, we want to know what it means. What is a number? It is not so obvious as one might think. Bertrand Russell said "A number is the class of all classes similar to a given class." I.e., all sets of three have something in common, which we could call "threeness."
Levels of Measurement
The first and most important question is: is the measure continuous or categorical? This is important because continuous variables are required for the use of statistics such as the mean, standard deviation, correlation and regression. With continuous measurement we have precise distances between the items measured, with categorical we just have them sorted into discrete categories.
If a variable is continuous, we can ask whether it is "interval" or "ratio". Both of these have precise distance measurement between points. In addition, ratio measures have a logically meaningful zero point. With ratio measures, we can talk about ratios between variables, e.g., say that $50 is twice as much money as $25. With interval variables, such as fahrenheit temperatures, we cannot make such statement.
If a variable is categorical, we can ask whether it is "dichotomous," "nominal" or "ordinal"
These terms are summarized on page 52 of the book.
Dichotomous variables have only two categories. These can be two natural categories such as "male' and "female" or they can be artificial "dummy" variables, such as: are you a Catholic or not;. With dichotomies you can use regression and correlation.
Nominal variables have more than two categories, but not in any order or with a measured distance between them.
Ordinal variables have the categories in a logical order (from "lower" to "higher").
In answering questions about measurement, give the highest or best level of measurement that is justified. Any variable that meets the criteria for a ratio variable also meets the criteria for an interval variable, but the criteria for a ratio variable are more stringent so we would say that it is ratio measurement. Any ordinal variable also meets the criteria for a nominal variable, but if it meets the criteria for ordinal we say it is ordinal.
It is important to understand that many variables can be measured at different levels. Thus I could take height and put it into categories such as short, medium, tall in which case I would be using ordinal measurement because they are in order. I could also measure it in inches or centimeters, which would be ratio measurement. It is also important to understand that each of the statistics is appropriate for variables measured in some ways but not others. Doing percentages and cross-tabulations makes sense for nominal or ordinal data. Chisquare is for nominal or ordinal data. Doing correlation or regression or means and standard deviations requires interval or ratio data. We can make a broad distinction between categorical (nominal or ordinal) or continuous (ratio or interval) data. The dichotomy is a special case because we can use correlation and regression with dichotomies, but we can also do percentages, cross tabulations and chisquares.
Nominal Measurement. Categories that could be put in any order.
Catholic, Protestant, Jewish, Moslem, LDS, Buddhist, Episcopalian, Baptist
variable one, category of religion, variable two denomination.
Mental illnesses (DSMIV) e.g., adjustment disorder, borderline personality disorder, paranoid schizophrenic
Crimes: burglary, assault, murder. What do these terms mean? Look at the US Criminal Code.
Each individual should go into one and only one category on a variable, one value on a variable. For example: What is your favorite food, we have a long list, but each person is allowed only one.
Sorting people into categories must be as reliable and accurate or valid as possible. One of the things we do is evaluate how accurate our measurement is.
Ordinal Measurement. Here we have categories in a logical order. Very short, short, medium, very tall, tall . Often we take continuous variables and make them ordinal. Income: Under $20,000 $20 to 40,000 $40 to 60,000 $60000 plus.
Interval Measurement: TEMPERATURE IN FAHRENHEIT OR CENTIGRADE, 0 degrees is not the absence of heat. How about the day that the "temperature doubled" in New York City?
Ratio Measurement: Income in dollars: a continous numerical value PLUS a meaningful zero point. Height in inches.
There is a "Levels of Measurement Review Quiz" available on WEBCT. This quiz is not required and does not count towards the grade. The correct answers are explained once you take the test.
February 2 -
Discussion of designing research projects. How do we decide what to study? Supplementary reading in Trochim on the structure of research. You may prefer his "hourglass" metaphor to the circular one on page 14 of our textbook.
- Selecting a topic. Typical motives include:
- Finding out something we don't know. This may include something local, e.g., what do people in Camden think about the new Governor's actions, something that has been unresolved in earlier research, something that hasn't been studied because it is new, etc. This is what the authors of your book mean when they say "research always starts with wondering."
- Another purpose that motivates research is proving to other people that what we "know" is true really is true. This is "advocacy" research, and it can be very one-sided and lead to sloppy work. Often this involves causal arguments, proving "why" something happens. This kind of research may not start with "wondering" but with "arguing."
- Answering a question posed to us by our employer or by a client, applied research. Here someone else really chooses the topic.
- Formulating a Research Question. This means formulating a "statement" which will involve variables. We have an argument or story in mind at this point.
- Defining the Concepts. Usually not a lot of time goes into this stage of empirical research, but some people do write articles focusing on this, e.g., what does "race" or "poverty" mean, what is the difference between "sex" and "gender" An example: the measurement of romantic love.
- Operationalizing the Concepts. A lot of effort goes into this. Quantitative research means you have to measure your variables and a lot depends on having good measurement. Sometimes this is difficult, e.g., measuring "intelligence" or "liberalism-conservatism" or "mental illness" or "crime rates (various kinds)". Often we use standard measures created by the government agencies that collect statistics.
- Formulating Hypotheses. This is usually pretty easy. There is a distinction between "null hypotheses" and regular hypotheses, which is explained on page 13. It means testing the hypothesis that your hypothesis is not true. Thus, you hope to "reject the null hypothesis" rather than "accept the (regular, not-null) hypothesis". So far as I know, there is no word for the opposite of Null, it might be Substantive? Type One Error: accepting that a relationship exists when it doesn't. Type two: rejecting a relationship when it really does exist.
- Making observations. This is a major step unless we just get the observations from someone who already did the work.
- Analyzing the Data. This is "number crunching" running data through the computer. Of course, one can also analyze qualitative data from interviews or observations, but today even that tends to get quantified (content analysis).
- Assessing the results. This is really part of the analysis. If the hypothesis doesn't work out, often researchers go back and change the hypotheses and pretend they knew all along what was going to happen
- Publishing the findings. This assumes that you are doing "scientific" or "pure" research, much applied research is actually distributed only within the organization that paid for it. This may be done in person, with a "power point" presentation. Refereed publications: you paper is sent to other specialists for review to decide if it should be published. "Refereed journal." Press release. Publication can be online as well as on paper. You publish the research so you can get credit, see your name in print, get promoted, and also so that you can inform others, and perhaps most important, so that other people can criticize or attempt to replicate it. Usually people replicate research in the hope of overthrowing it, if you just find the same thing as before, there is less interest. This cancels out a lot of the bias in social research, since there is usually someone with the opposite bias to correct it.
By "science" we mean a field of study that attempts to establish generalizations based on empirical observation. Establishing generalizations means we need abstract concepts. This is different from establishing facts about particular cases as we may do in history or in criminal investigation. In a criminal investigation, we may ask "who is committing the rapes on campus" and we work very hard to find that person. In scientific research, we would say, what factors determine the frequency of rape in different communities or on different campuses. The first helps to solve a case, the second helps us to formulate policies that may lessen crime in the future. We may also use the generalizations as guidelines in solving a particular crime, e.g, usually rapes are committed by men with certain characteristics... But this is risky, and may get us into legal trouble, particularly if we use racial or ethnic characteristics, e.g., racial profiling. It may be that cocaine smugglers are largely Hispanic, for example, but this is of little use in catching them and may lead us to hassle a lot of innocent people since the vast majority of Hispanic people are not smugglers.
Establishing general patterns can help us to change policies. An example is the work of Florence Nightingale who used social research to advocate for better nursing care in the British armed forces during the Boer War. She invented the bar graph and pie chart.
Other fields of knowledge also use concepts, concepts are a part of how the human mind and perhaps all intelligences work. Philosophy is largely about analyzing the implications of different concepts. Mathematics also deals with concepts because numbers are concepts. The small integers are especially important, especially Zero and One (or nothing and something). Religion uses concepts The Bible says In the beginning there was the Word, and the Word was with God, and the Word was God. What does that mean? The original Greek text uses the word "logos" which means unit of thought or idea or concept, which is where we begin also, with concepts. How do we decide if this is a good concept or not? We may find it fulfilling, spiritually meaningful. We may find it beautiful. Social science, however, is not much concerned with that. We are much more mundane, we want useful, pragmatic concepts. Religious concepts are good if they provoke spiritual reflection, as in reciting a Mantra in Buddhism. Literary concepts are good if they are beautiful, which social sciences seldom are. W.H. Auden's poem Under Which Lyre is an aesthetic attack on social science and other applied sciences.
Social science may not appeal to poets, but it is more useful. At least there are more jobs using social science than writing poetry. In the social science we want concepts that are parsimonious and useful and clearly defined. We avoid ambiguity and subtleness, traits which literature and religion may value. We are not, however, looking for concepts that are logically correct in the way that philosophy does. We want concepts that help us to make useful discoveries about the observable world. We like concepts that are falsifiable, which is a key difference between social science and theology or mathematics. This is an issue now in the debate about "intelligent design" theory, a doctrine that claims to be a scientific theory but many say is a theology in disguise. Is there any evidence that would disprove this theory. Is the human body intelligently designed or did it evolve? Why do we have an appendix? Why do men have non-functional breasts? Why are our backs weak like the backs of quadrapeds? Why do whales have finger bones in their fins?
In social science we have general ideas or theories, which are statements of relationships between concepts. From these, we make hypotheses about what we are likely to observe in empirical reality. We gather data to test our hypotheses, and we change our theories if the tests do not work out. At least that is how it is supposed to work! An excellent example is the work of Felton Earls and his colleagues who sed a combination of research methods to study the causes of urban crime. Their organizing concept was "collective efficacy".
In real life, many social scientists act more like lawyers, selecting facts that support their preconceptions. We are more successful in being objective in our descriptions than in our explanations or in our predictions. We know that the rate has been going down for the last fifteen years or so, but we are not agreed about why.
The book distinguished "pure" from "applied" and "evaluation" research. Pure research is motivated entirely by scientific curiosity, applied research seeks to further a goal. Evaluation research seeks to determine whether a particular program works or not.
In testing hypotheses, we can make Type One or Type Two errors. Type One: accepting a correlation that does not exist. Type two: Not accepting a correlation that does in fact exist. There is a trade-off between the two, to the extent that we avoid making Type One error we increase the risk of Type Two error.
The null hypothesis is a statement of how things would be if our theory were not true, generally if there was no relationship between our variables. Some philosophers believe it is more correct to say "we reject our null hypothesis" than to say "we accept our hypothesis as true".
January 26 - we will go The Research Process Using Aggregate Data from the workbook and perhaps introduce chapter one: concepts and theories
In interpreting a correlation coefficient: first look if it is positive or negative. This tells whether the variables are positively or negatively related. Then look for an asterisk. If it doesn't have one, it is not "statistically significant," i.e., it might have just been a rrandom chance. Two asterisks are better than one. Then look at the number. They vary from 0 to plus or minus one. The closer the absolute value is to one, the stronger the relatinship. If you square it you get the "percentage of the variance explained", i.e, if you known the value on one variable, you can explain 85% of the variation on the other.
When you see Prob = .0000 that means that the probability of this relationship occurring by chance is very low, almost zero, with 50 cases drawn at random.
The line equation. The simplet line equation is y = x.
Correlation matrix, shows a set of correlations between variables. You can look down the column or along the row and find each pair.
Multiple regression: one dependent variable and a set of independent variables. The "beta" tells us how well each predicts the dependent variable, controlling for the others. The Multiple R Squared tells us how much variance is explained.
January 24:
Let's go over the computation of row, column and total percents and also expected frequencies in cross-tabulation tables. . For this purpose we will use a simple 2 by 2 distribution as follows. The variables are gender and opinion on an issue, each of which has two values:
25 men agreed
17 men disagreed
65 women agreed
30 women disagreed
The first thing we do is put them in a two dimensional table, as
follows and compute the row totals, the column totals and the grand
totals.
| Observed Frequencies or Obtained Frequencies | Men | Women | total |
| Agree | 25 | 65 | 90 |
| disagree | 17 | 30 |
47 |
| total | 42 | 95 |
137 |
To get the column percents, we divide the cell frequencies by the
column total, then multiply by 100 to get a per cent. Thus, if I
ask, "what percent of the men
agree" the answer is 25/42 *100
= 59.5%. The base of this percent is the number of
men. This is a column percent because the men are in a column.
If I ask, "What percent of
those who agree are men," the answer
is 25/90 * 100 = 27.8%,. The base of this percent is
the number of people who agree. This is a row percent because the
people who agree are all in a row.
If I ask, "What percent of
the respondents are men who agree," the
answer is 25/137*100 = 18.2%. The base of this percent is
the total number of respondents. This is called a total percent
because the base is the total number of people.
We can compute expected frequencies, based
on the null hypothesis that
men and women do not differ in their opinions. We can compute
these
knowing only the marginal or total frequencies. The easy way to
compute them is to multiple the row total for each cell by the column
total for that cell, then divide by the grand total.
Expected Frequencies - rt *ct /gt
You can see examples of these with the Percents,
Expected Frequencies and Chi-Square Calculator (an Excel
spreadsheet).
This also calculates the chisquare statistic which is given by the
formula (ObservedFrequency-Expected Frequency)2/ExpectedFrequency.
You can then look this up in a table in the back of a statistic book to
find out if the difference between expected and observed is
"statistically significant".
| Expected Frequencies | men | women | total |
| agree | 90*42/137=27.59 | 90*95/137=62.41 | 90 |
| disagree | 47*42/137=14.41 | 47*95/137=32.59 | 47 |
| total | 42 | 95 |
137 |
Consider the following answers to the question "I believe that marinated artichoke hearts should be the national vegetable."
65 men agreed
| Male |
Female |
Total |
|
| Agree |
65 |
25 |
90 |
| Disagree |
85 |
105 |
190 |
| 150 |
130 |
280 |
25 women agreed
85 men disagreed
105 women disagreed
Answer the following questions:
What percent of the men agreed?
PCT1 . .
This is a colum percent because
the men are a column. 65/150 * 100 43.3%
What percent of the women disagreed?
PCT2 . .
Also a column percent
105/130 * 100 = 80.8%
What percent of those who agreed were men?
PCT3 . .
This is a row percent. The
row is the Agree row, the total is 90. the men who agree are
65 65/90 * 100 72.2%
What percent of those who disagreed were women?
PCT4 .
.
105/190
What percent of the respondents agreed?
PCT5 .
.
The number who agreed divided by
the grand total. 90/280 32.1%
What percent of the respondents were women?
PCT6 . .
Fill in the Table:
Gender and Belief that the Marinated Artichoke
Hearts
Should be the National Vegetable
| Men | Women | Total | |
| Agree | . | . | . |
| Disagree | . | PCT7 . . | . |
| . | 100% |
100% |
100% |
This table asks for column percents because they add to 100%. to get what % of the women disagreed, as asked for, divide the women who disagreed by the total number of women.
| Men | Women | Total | |
| Agree | PCT8. .21.1 | . 23.9 |
45 |
| Disagree | .53.9 | PCT9 . .61.1 |
115 |
| . | 75 |
85 | 160 |
This is
establishing a "null hypothesis" that gender and opinion do not
matter. The expected frequency is what we would "expect" on the
null
hypothesis that there is no relationship between the variables. The easy way to
compute them is to multiple the row total for each cell by the column
total for that cell, then divide by the grand total.
Expected Frequencies - rt *ct /gt
MEN WHO DISAGREE 75*115 /160 = 53.9
women who agree 85 * 45 /160 23.9
women who disagree 85 * 115 /160 = 61.1
January 19
733 men said yes
954 women said yes
43 men said no
73 men said no
Frequencies:
Male Female Total
Yes 733 954 1687
No 43 73 116
Total 776 1027 1803
Fiver statements I could make about the number 954:
954 women said yes.
What percent of the women said yes? 954/1027 = 92.9%
What percent of the respondents who said yes are women? 954/1687 * 100 = 56.6%
What percent of the respondents are women who said yes? 954/1803 = 52.9%
On the "null hypothesis" that there is no relationship between sex and opinion on this item, how many women would we "expect" to say yes. To get this, multiply the row total by the column total, then divide by the grand total. 1687*1027/1803
January 17 to be continued on January 24
We will begin with Chapter 6 on Basic Research Design because it gives a good introduction to the kinds of research social scientists actually do. . How research is organized or structured to accomplish different ends. The book discusses four "basic" types of designs. The "Review Glossary" on page 124 is a good place to find a brief description of each.
- The experiment - subjects are recruited to be exposed
to a hypothesized causal factor, called the "independent
variable". They are assigned at random to experimental and
control groups. The effect of the independent variable on a
hypothesized effect or "dependent variable" is measured. This is
the best method for establishing causal relationships, so long as you
can set up an experimental situation that is sufficiently close to real
life.
- Survey Research - A standardized set of questions is asked
to a representative sample of people. Very widely used because it
is quick and efficient and gets good information about attitudes and
behaviors that people are aware of and are willing to tell us
about.
- Field Research - We go out into the world and observe what
actually
goes on. This gets at real behavior in its real setting, with the
only difference being the presence of the researcher.
- Aggregate or Comparative Research - We analyze statistics
collected
by government or other organizations. This depends on the quality
of the data. Very widely used in criminal justice because the CJ
system collects a great deal of data. It is often referred to as
the COMSTAT method.